When Classifications Change but Deadlines Don’t: Scaling Recoding with LLMs
The NACE Transition at Insee
Insee — French National Institute of Statistics and Economic Studies
2026-04-06
Outline
1 1. The Problem
1.1 Statistical classifications, briefly
The Problem
Public statistics rely on shared classifications
- They are what makes aggregated numbers comparable
- We aggregate millions of businesses, jobs, or products…
- Need shared coding systems
What NACE is
- The EU classification of economic activities
- Every business unit in production registers gets a NACE code
- Hierarchical: section → division → group → class → sub-class
- Revised every ~15 years — the current move: NACE 2.0 → NACE 2.1
1.2 When a classification is revised
The Problem
A recurring challenge for every statistical institute (NACE, COICOP, ISCO, …).
Standard ML maintenance
- Inputs may drift over time
- We monitor and retrain on fresh labels
- The target variable stays the same
Classification revision
- The target variable itself changes
- New labelled data are scarce or missing
- Legacy labels are in the wrong space
- Standard retraining is not possible
- At Insee, a TorchTextClassifiers classifier (fastText-inspired) in production since 2023 to assign NACE 2.0 codes
- Trained on a 2.7-million-label training set.
Central question: how can we leverage years of accumulated production knowledge in the old classification to bootstrap a model in the new one?
1.3 Our strategy: shifting the old trainset
The Problem

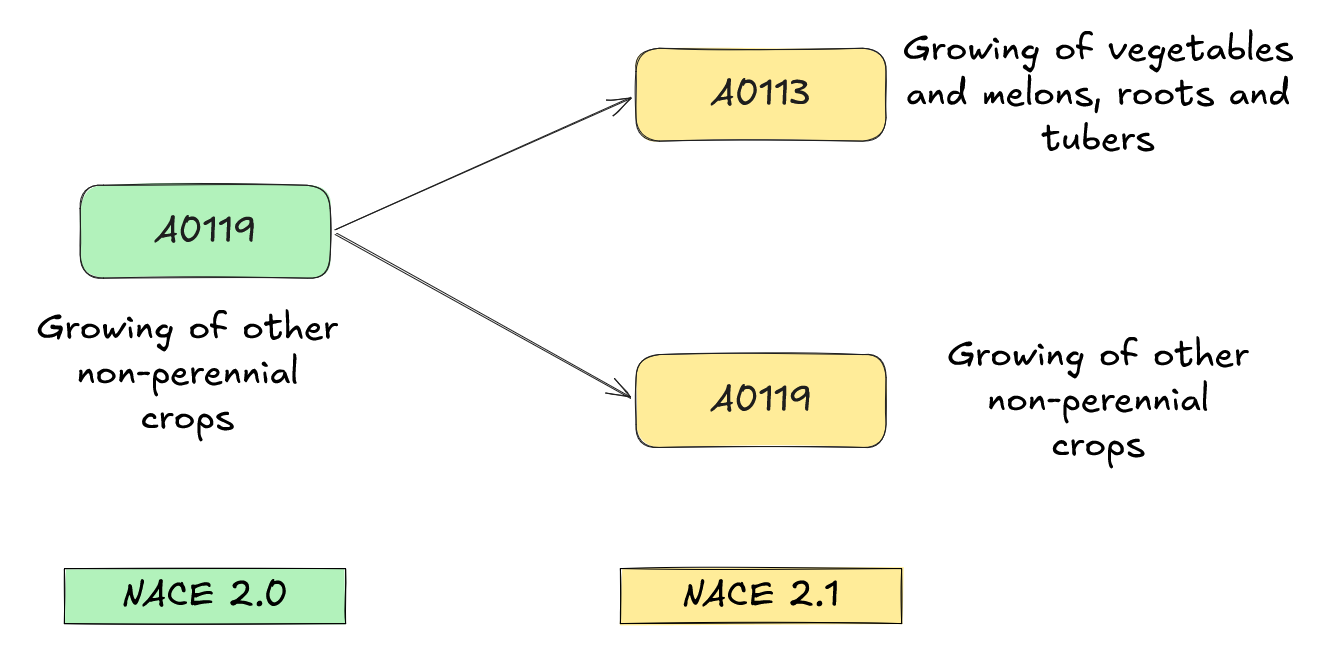
1.4 NACE 2.0 → 2.1 and the multivocal codes
The Problem
Scope of the change
- Change in the number of sub-classes? Moderate…
- from 746 to 732
- Mostly splits at level 4, with a few merges and recompositions
Complexity lies in non-bijective cases!
- Univocal: one-to-one mapping
- Multivocal: 1-to-many relation (~2 to 5)
1.5 The scale of the problem
The Problem
| Multivocal | Univocal | |
|---|---|---|
| Correspondence table | 25 % | 75 % |
| Actual training set | 52 % | 48 % |
~1.4 M
observations that cannot be recoded by table lookup
The problem cannot be solved by a deterministic mapping table alone.
2 2. Human and Virtual Annotation
2.1 Human ground truth, machine scaling
Human and Virtual Annotation
NACE 2.1 ground truth campaign
- ~30k annotations directly in NACE 2.1
- ~25 NACE experts
- Focused on multivocal cases (the hard ones)
What we learned
Expert agreement is imperfect
- 3-experts blind re-annotation: 62 % strict agreement, 96 % majority
- Experts are far from converging systematically: we stay cautious when interpreting our precision metrics
Explicit reasoning protocol
- Description, then check the legacy code, then consult candidates and explanatory notes, then decide
- A sequence we can encode into an LLM prompt at scale
3 3. Methodology
3.1 Rule-Based Augmented Generation as
constrained selection
Methodology
Why not ask the LLM directly?
- 732 codes is too large a space for reliable open generation.
- Hallucinations are very frequent.
Constrained selection instead:
- For each observation, we already know the NACE 2.0 code
- The correspondence table gives the set of admissible NACE 2.1 codes
- The task becomes: pick the right code from a short, restricted list
- Output aligned with official rules
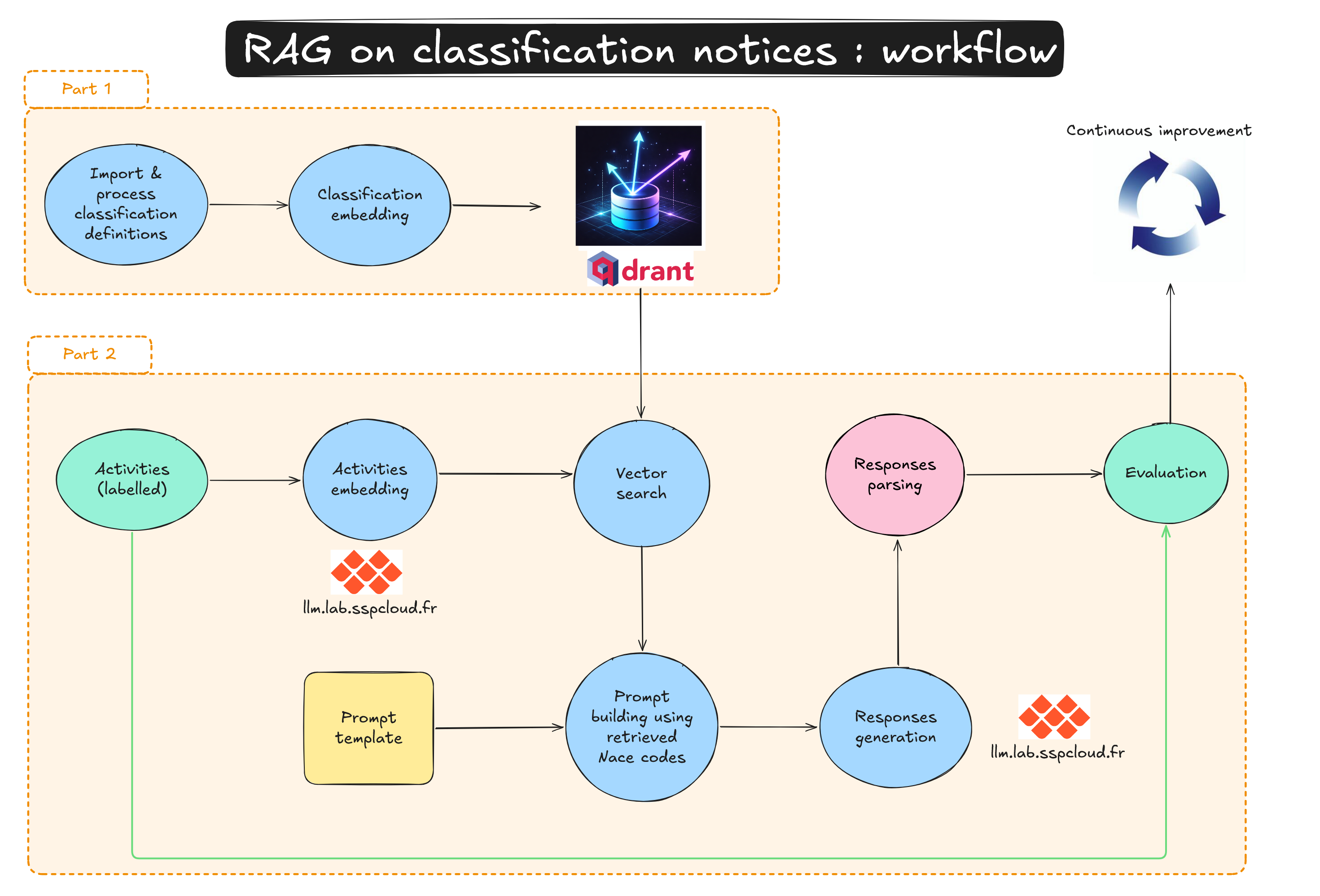
3.2 The pipeline
Methodology
For each observation:
- Retrieve the activity description (free text + optional precisions: secondary activity, legal category)
- Retrieve the legacy NACE 2.0 code
- Use the correspondence table to get the set of candidate NACE 2.1 codes
- Inject the explanatory notes of each candidate code into the prompt
- Ask the LLM to pick the most appropriate code
- Parse the structured JSON response
A form of Rule-Based Augmented Generation (RBAG) with a deterministic retriever.
Inputs to the prompt
| Element | Source |
|---|---|
| Activity text + precisions | Production register |
| NACE 2.0 code | Insee NACE Experts |
| Candidate set | Correspondence table |
| Explanatory notes | Official NACE 2.1 documentation |
3.3 The prompt structure
Methodology
System prompt — same for every observation
You are an expert in the NACE classification. Your task is to assign a NACE 2.1 code to a business based on its activity description, using a candidate list derived from the existing NACE 2.0 code…
User prompt — observation-specific
# Main activity : {{activity}}
# NACE 2.0 code : {{nace_old}}
# Candidate NACE 2.1 codes + notes : {{proposed_codes}}
========
# Instructions (7 rules)
→ candidate list only — no external code
→ first activity only
→ strict JSON — no explanation{proposed_codes} — example:
86.95: Physiotherapy activities
Includes: physiotherapy, medical massage, occupational therapy, praxitherapy…
Does not include: osteopaths, chiropractors, non-medical massage parlors…
86.96: Traditional, complementary, and alternative medicine [...]
86.99: Other human health activities n.e.c. [...]3.4 Multi-model annotation
Methodology
| Model | Size | Inference speed | Behaviour |
|---|---|---|---|
| Qwen3-6-35B MoE | 35B | Very fast (13 it/s) | Moderately restrictive |
| Qwen3-6-35B MoE + thinking | 35B | Less fast (1 it/s) | Less restrictive |
| Gemma4-26B MoE | 26B | Fast (8 it/s) | Moderately restrictive |
➕️ Aggregation: majority vote.
Different sizes, different throughput.
4 4. Infrastructure
4.1 Our MLOps stack on the SSPCloud
Infrastructure
SSPCloud is Insee’s data science platform, built on the open-source Onyxia project and powered by Kubernetes as its underlying technology stack.
Main elements of the technical stack:
- MinIO — S3-compatible storage for datasets and model artifacts
- llm.lab — SSPCloud’s LLM provider on premise, (OpenWebUI + vLLM)
- Langfuse — prompt versioning
- MLflow — experiment tracking
- Argo Workflows — the end-to-end pipeline orchestrator








Entirely open-source, containerised, reproducible.
5 5. Results
5.1 Grading the LLM annotators
Results
- Reference: the ~30,000 manually annotated multivocal cases (NACE 2.1, level 5)
- Three complementary accuracies — at the most detailed level (sub-class):
- Overall — across all observations
- Codable subset — restricted to predictions the LLM itself flagged as codable
- LLM-only: restricted to cases where the true code is in the candidate list (isolates the LLM’s choice quality)
5.2 Per-model and ensemble accuracy
Results
Accuracies at level 5 (sub-class) — % of cases where the predicted code matches the manual annotation.
| Model | Inference | Overall | Codable | LLM-only |
|---|---|---|---|---|
| Qwen3-6-35B MoE | 13 it/s | 75.2 % | 78.3 % | 83.3 % |
| Qwen3-6-35B MoE + thinking | ~1 it/s | 75.7 % | 80.4 % | 84.1 % |
| Gemma4-26B MoE | 8 it/s | 75.2 % | 80.0 % | 83.5 % |
| Majority vote | — | 78.3 % | — | 86.9 % |
The codable filter is per-model, hence the dash for the ensemble vote.
Ensemble accuracy comes at a real cost: three full inference passes, one of them in thinking mode (~10× slower).
A substantial share of disagreements are not LLM errors but ambiguous descriptions or legacy-coding mistakes.
5.3 A note on self-reported confidence
Results
- Hoped use: filter low-confidence predictions
- Observed (all three LLMs):
- models are overconfident,
- correct and incorrect distributions overlap,
- raising the threshold trims coverage faster than it lifts precision
Self-reported confidence is not a reliable filter on its own.
5.4 Reconstructing the training set
Results
Once happy with the LLM on the benchmark, we apply at scale:
- ~1.0 M multivocal observations relabelled via the LLM pipeline
- Combined with 1.3 M univocal observations (table lookup)
- ~2.3 M labels in NACE 2.1
- Distribution across predicted codes is very close to the labelled distribution
Tip
This is semi-synthetic training set: real businesses, real descriptions, but algorithmic labels.
5.5 Performance of the retrained classifier
Results
TorchTextClassifiers retrained on the semi-synthetic corpus
~80 %
overall accuracy on a representative NACE 2.1 test set
≈ the legacy NACE 2.0 classifier on its NACE 2.0 task
Last retrain used an earlier vintage of the corpus; today’s pipeline produces better labels.
Semi-synthetic LLM-generated labels can substitute for manual annotations in the early stages of a classification transition.
6 6. An Alternative: Pure RAG
6.1 Why try a pure RAG approach?
An Alternative: Pure RAG
Limitations of RBAG
- Relies on legacy NACE 2.0 labels → any annotation error in the old system is propagated into the new corpus
- Requires an official correspondence table — not always available
- Tied to the specific case of a revision of an existing classification
What RAG brings
- No propagation of legacy labelling errors
- Works when no historical labels exist — new classifications, new domains, brand-new use cases
- A more general pipeline for any automatic coding task
- Gives us an empirical benchmark: how does RAG compare to RBAG in accuracy?
Even where RBAG works, RAG is worth mastering — and quantifying.
6.2 What a RAG pipeline looks like
An Alternative: Pure RAG
6.3 RAG vs RBAG: results
An Alternative: Pure RAG
qwen3-6-35b-moe · 28,499 multivocal obs · only the candidate-set source differs
Level-5 accuracy decomposition
| RBAG | Pure RAG | |
|---|---|---|
| Truth in candidate set | 90.0 % | 83.5 % |
| LLM picks right (when in set) | 83.4 % | 78.1 % |
| Overall | 75.3 % | 65.3 % |
The retriever is the bottleneck
- RBAG floor: legacy NACE 2.0 mislabel rate (~10 %)
- RAG floor: retriever miss in top-5 (~16.5 %)
- Candidate-set gap (6.5 pts) > LLM-choice gap (3 pts)
- Larger top-k is a wash: retriever recall ↑ but LLM choice ↓
Closing the gap needs better retriever quality (embeddings, reranker) — not a wider top-k.
7 7. Conclusion and Perspectives
7.1 Take-aways and what’s next
Conclusion and Perspectives
Take-aways
- A practical method to handle classification revisions in production ML
- LLMs as virtual annotators scale where humans cannot
- Semi-synthetic labels reach production-grade accuracy (~80 %)
- Fully open-source, reproducible MLOps stack
Limits & ongoing work
- Inference cost is non-trivial at ~1 M queries
- Legacy errors are inherited
- Improving the RAG variant — embeddings, rerankers, hierarchy-aware retrieval
- Extending to COICOP
- Julien PRAMIL
- Data Scientist
- Innovation Lab
- Insee — France
- julien.pramil@insee.fr








